Prometheus est devenu un standard pour la supervision des environnements Cloud et architecturés sous forme de micro services. Bien que puissant et simple à prendre en main, son mécanisme de stockage des données peut être difficile à comprendre aux premiers abords, surtout si vous devez estimez la taille nécessaire qu’il faut pour stocker toutes vos métriques pendant une durée de retention.
Comment le stockage Prometheus fonctionne ?
Une fois collectées depuis les exporters, les données sont sauvegardées dans une base de données local (souvent sur /var/lib/prometheus ). Elles sont divisées en bloc de 2 heures et traitées différemment.
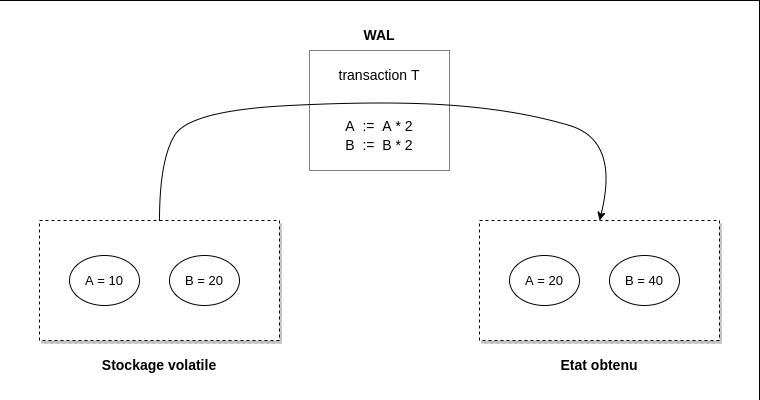
Le bloc courant est gardé en mémoire et n’est pas complètement persistent mais résiste à un redémarrage du serveur grâce à un mécanisme de WAL (Write-Ahead Logs). C’est-à-dire qu’au lieu de stocker toutes les données, on stocke uniquement les transactions nécessaires pour passer du dernier état sauvegardé à l’état actuel.
Pour les blocs passés, ils sont séparés dans un repertoire différent. Chaque dossier contient tous les échantillons de données pour la période donnée, eux-mêmes divisés en morceaux de 512 Mo dans un dossier chunks, un fichier de métadonnées et un fichier d’index. Ce dernier permet l’indexation des noms des métriques et des labels contenus dans le dossier. De plus, quand les données sont demandées à être supprimés, elles sont d’abord déplacés dans un dossier tombstones puis supprimées ultérieurement. A noter, qu’il existe des mécanismes de compactage au niveau des séries passées qui regroupe des blocs de 2 heures afin de réduire leur taille totale.
Voilà donc ce que vous pouvez trouver si vous inspectez votre dossier Prometheus :
$ tree -L 3 /var/lib/prometheus
/var/lib/prometheus/
├── 01FNPQMG7PMBTG9HE6TG0GA8ZV
│ ├── chunks
│ │ ├── 000001
│ │ └── 000002
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01FS2WMWT2TXMJGM4JKA553WFA
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── chunks_head
│ ├── 001091
│ └── 001092
└── wal
├── 00001098
├── 00001099
├── 00001100
├── 00001101
└── checkpoint.00001097
└── 00000000Estimer la taille de votre stockage Prometheus
Maintenant que vous (et moi aussi) en savez un peu plus sur comment le stockage Prometheus fonctionne, on va s’intéresser sur l’espace de stockage nécessaire pour sauvegarder toutes ces données. C’est notamment utile pour dimensionner votre serveur de monitoring ou un volume persistent dans le cadre d’infrastructures micro-service (Kubernetes).
La documentation officielle est, de nouveau, très utile sur ce sujet. Elle nous donne la formule suivante :
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sampleIl s’agit d’une simple multiplication entre trois valeurs :
- La durée de rétention des données en secondes
- Le nombre d’échantillons ingérées par seconde
- Le taille en octets d’un échantillon. La documentation signale qu’en moyenne cette valeur se trouve entre 1 et 2 octets.
La donnée la plus difficile à avoir est la deuxième. Pour ce faire, il faut faire la somme du nombre d’échantillons par cible (target) divisée par l’intervalle de collecte du serveur. Par exemple, imaginons que vous avez deux targets sur votre serveur :
| Nom | Intervalle de collecte (s) | Nb observations |
|---|---|---|
| A | 30 | 60 |
| B | 20 | 120 |
Pour la A, il y a 60 séries en 30 secondes, ce qui fait 2 échantillons par seconde. En appliquant le même raisonnement pour B, on en obtient 6. En additionnant les deux, ça fait 8 (technique !) et pour conserver ces données pendant un mois, il faudra :
2592000 * 8 * 2 = 41,5 Mo (41472000 octets) Si vous avez beaucoup de cibles sur votre serveur, j’ai crée un petit script Python utilisant l’API de Prometheus pour toutes les récupérer et compter le nombre d’échantillons pour chacune d’entre elle. Vous pouvez trouver le code source sur ce gist Github.
Son utilisation est assez simple : il suffit de lancer le programme en mettant en paramètre l’URL de votre serveur Prometheus et la retention voulue. Faisons le test sur mon serveur pour voir si le résultat du script correspond à la taille réelle du stockage Prometheus
$ python3 main.py http://localhost:9090 90d
Target : netdata
Scrape Interval : 15
Nb. Samples : 2666
Target : prometheus
Scrape Interval : 15
Nb. Samples : 661
Target : suivi-bourse
Scrape Interval : 120
Nb. Samples : 57
------
Time retention (s): 7776000
Nb Samples per seconds: 222
Estimated Size (bytes): 3.452544e+09
$ sudo du -h -d 0 /var/lib/prometheus/
4.0G /var/lib/prometheus/Il y a une petite différence de 500Mo entre la réalité et le script mais cela peut s’expliquer par les inodes ou la présence des autres fichiers dans le dossier (index, meta.json) qui ne sont pas pris en compte dans le calcul.
Cet article vous a plu ? N'hésitez pas à le partager et à utiliser le script à votre disposition !

